시작에 앞서
나는 창업했을 당시에 같이 계시던 개발자분에게 처음 들었었다. 에러 핸들링도 한 적은 있긴 했을까, 스스로 기억도 없는데 이런 걸 처음 알려줬다.
그냥 쓰라길래 썼지만, 좀 신세계였던 것 같다. 가장 화나는 일이 뭘까 손에 꼽자면
“내 컴퓨터에서는 잘 되는데” 꼭 다른 사람은 안 된다는 게 가장 열받는 게 아닐까?
그때 어떤 환경에서, 무슨 일을 하다가 에러가 났는지 확인할 수 있는 게 가장 충격적인 포인트가 아니였나 싶다.
기본적으로 Sentry는 뭘까?
공식문서에는 이렇게 적혀있다.
Sentry is a software monitoring tool that helps developers identify and debug performance issues and errors. From end-to-end distributed tracing to performance monitoring, Sentry provides code-level observability that makes it easy to diagnose issues and learn continuously about your application code health across systems and services.
개발자가 성능 문제와 오류를 식별하고 디버깅하는 데 도움이 되는 소프트웨어 모니터링 도구이다.
try { … } catch { … } 했을 때 예외(오류)를 자동으로 포착하고, 오류를 분류하고 확인하여 관리할 수 있게 도와준다.
처음에는 프론트엔드에서만 사용했지만, 백엔드도 지원을 해준다. 몇 년 전에 사용했을 때는 지원하는 프레임워크가 그리 많지 않았지만, 지금은 많은 프레임워크를 지원한다.
Sentry의 가장 큰 장점은 쉽게 사용해볼 수 있다는 점인데, Tracing도 바로 도입해볼 수 있다.
Tracing
Tracing이란 프로그램의 실행에 관한 정보를 기록하기 위한 로깅의 특별한 사용이라고 한다. 이를 통해서 애플리케이션에서 발생하는 “모든 상황”을 전체적으로 파악할 수 있다.
Logging vs Tracing
두 개 모두 시스템의 상태를 파악하기 위해서 사용하지만, Tracing은 연속적으로 요청이 어디서부터 얼마나 걸렸고, 어디로 진행됐는지를 파악하기 위한 거라면, Logging은 특정 시점에 무슨 일이 있었는지를 확인한다고 보면 될 것 같다.
Logging
[2026-04-14 21:00:00] [ERROR] OrderService - 결제 처리 중 잔액 부족 발생 (UserID: 12345)Tracing
API Gateway 접속 → Auth 서비스 확인 → Order 서비스 로직 실행 → DB 쿼리 수행까지의 전체 타임라인TMI ) 오늘도 팀원이 “sentry에서 지금 trace 쓰이고 있나요”라고 물어봤다. 이럴 때를 대비해서 트레이싱이 뭔지는 알아두도록 하자.
왜 써야 하는 걸까?
1. 쉽고 간단한데 강력하다
이게 내가 생각하는 가장 큰 강점이다. Sentry를 대체할 수 있는 건 많다. OpenTelemetry, Rollbar, DataDog 등. 하지만 내가 써본 것 중에 가장 단단하고 직관적인데 너무 훌륭한 것 같다. DSN 하나만 넣어주면 바로 작동한다. 따로 구축할 필요도 없고, 유료 플랜이 있긴 하지만 초기에는 몇 개의 프로젝트 로그들을 다 받아도 크게 무리없다.
2. Breadcrumbs
에러 수집을 하고, 상세 페이지로 이동하면 사용자가 “뭐 하다” 터졌는지 확인이 가능하다. 사용자가 입력한 순서대로 타임라인이 나와있고, 뭐 하다가 터졌는지 쉽게 확인이 가능하다.
3. 난독화된 코드 복구
배포되고 나면 코드가 난독화가 진행돼서 알 수 없는 곳에서 이상한 에러가 나서 확인이 어렵지만, Sentry에서는 Source Map을 자동으로 업로드해서 에러를 정확히 보여준다.
4. Grouping
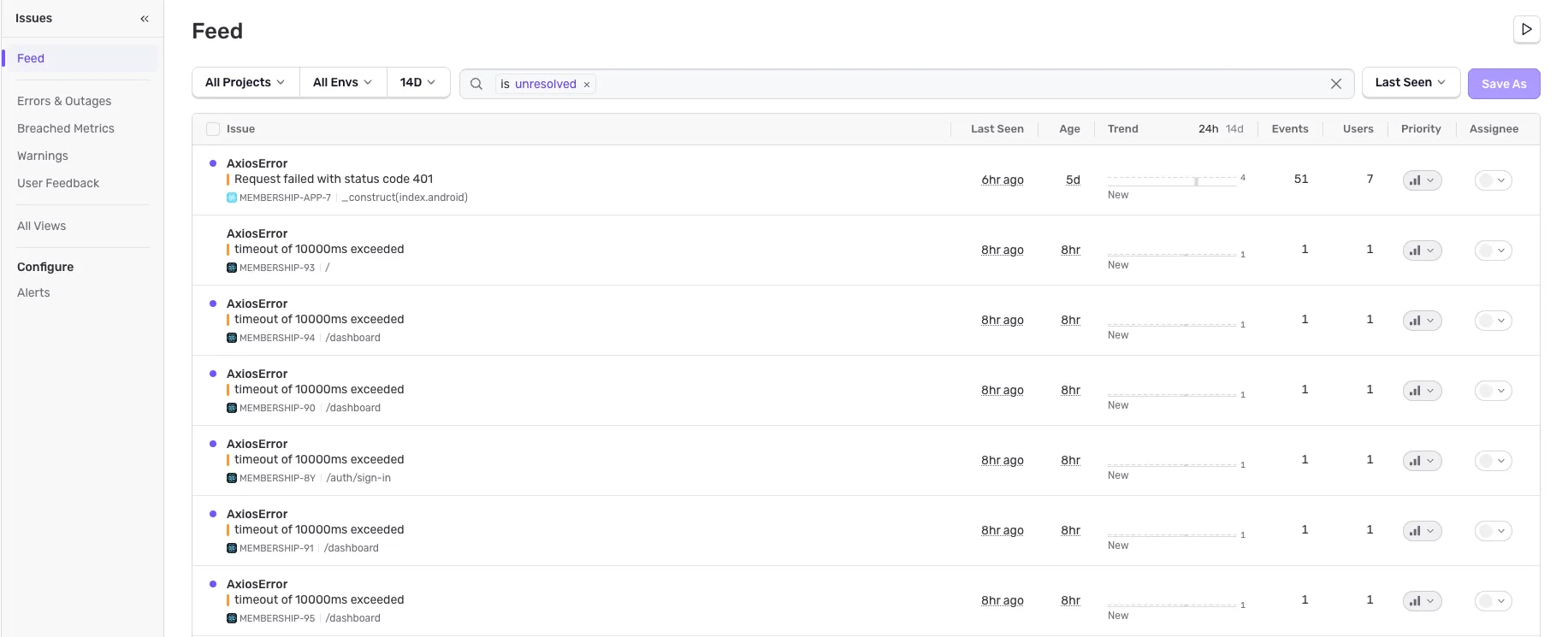
현재 내가 회사에서 수집하고 있는 에러 중 Timeout이라는 에러가 좀 자주 발생한다. 이게 하루에 몇십 건, 몇백 건이 쌓일 때도 있는데, 이걸 그룹핑해서 시간대별로 해당 시간에 동일한 에러가 몇 번이 났는지, 하나의 에러로 묶어주고 상세 페이지에서 확인이 가능하다. 그렇기 때문에 에러들이 발생했을 때 어떤 에러가 빈번하게 발생을 했고, 우선순위를 정하는 데 도움이 된다.
5. Release 연동
이건 앱 할 때 너무 유용했던 것 같다. 사용자가 자동 업데이트를 사용하지 않거나, 강제 업데이트를 하지 않는 경우 사용자마다 앱 버전이 다를 때가 존재하게 된다. 그때, 특정 버전에서 에러가 발생하면 어떤 버전에서 에러가 발생했는지 확인이 가능하다. 그럼 강제 업데이트를 시켜주거나, Expo를 사용하고 있기 때문에 eas update를 이용해서 빠른 대처가 가능하다.
한마디로 서비스를 운영하면서 발생하는 모든 상황을 쉽게 확인할 수 있다는 것이다.
프로젝트에 도입하기
공식문서만 봐도 쉽게 따라할 수 있다. 그렇기 때문에 좀 더 잘 쓰는 방법을 알아보려고 한다.
나는 JavaScript를 사용하기 때문에 JS 기준으로 보자면 기본적인 코드는 아래와 같다.
import * as Sentry from "@sentry/react";
Sentry.init({
dsn: "your_DSN_key",
integrations: [
Sentry.browserTracingIntegration(),
Sentry.replayIntegration(),
],
// Tracing
tracesSampleRate: 1.0,
tracePropagationTargets: ["localhost", /^https:\/\/yourserver\.io\/api/],
// Session Replay
replaysSessionSampleRate: 0.1,
replaysOnErrorSampleRate: 1.0,
});DSN
DSN은 말 그대로 주소다(Data Source Name). Sentry에서 프로젝트를 만들면 DSN을 주는데, .env에 넣어놓고 prod 환경에서만 작동할 수 있도록 하면 된다.
Integrations
Sentry의 기능을 확장하는 플러그인으로 browserTracing(성능 측정), replay(세션 녹화)와 같은 기능들이 있다. Replay는 진짜 유용하다. 사용자들이 무슨 일을 하다가 에러가 발생했는지 쉽게 확인할 수 있다.
tracesSampleRate
전체 트랜잭션 중 성능 데이터를 수집할 비율을 지정하는데, 1.0은 100%를 수집한다는 의미이다.
tracePropagationTargets
분산 트레이싱을 허용할 도메인 목록으로, 여기에 적힌 주소로 요청을 할 때만 Sentry의 트레이스 헤더를 붙인다. 해당 설정을 하면 백엔드 API를 호출하다가 에러가 발생했을 때, 백엔드의 어떤 로직이 문제였는지를 쉽게 찾아갈 수 있다.
replaysSessionSampleRate
에러 여부와 상관없이 전체 세션을 녹화할 비율을 의미한다. 0.1은 사용자의 10%만 녹화한다는 뜻이다.
replaysOnErrorSampleRate
에러가 발생했을 때만 해당 세션을 100% 녹화하여 전송한다. 에러 재현을 위해 보통 1.0으로 설정한다.
replaysSessionSampleRate와 replaysOnErrorSampleRate가 유사할 텐데, 모든 사용자의 세션을 녹화하면 성능에 부하가 걸린다. 그래서 보통 0.1 정도로 샘플링해서 흐름만 확인하고, “에러가 났을 때” 어떤 상황에 에러가 발생했는지를 파악한다고 보면 된다.
beforeSend
민감한 정보를 마스킹할 여부를 정한다. 기본적으로 사용자의 이름이나 이메일, 전화번호, 카드번호 등 유저의 민감한 정보들을 Sentry로 보내기 전에 제거하고 보낼 때 사용한다. 나는 기본적으로 값도 알아야 테스트할 수 있다는 생각 때문에 따로 필터를 걸지 않지만, 보안이 중요하다고 생각되는 경우에는 유용한 기능이라고 생각한다.
코드에서 활용하기
설정만으로도 충분하지만, 좀 더 꼼꼼하게 에러를 확인하기 위해 코드 내에서 직접 사용해보자.
captureException
에러를 Sentry로 보낼 수 있도록 도와준다. 객체나 문자열로 전송이 가능하다.
import * as Sentry from "@sentry/react";
async function fetchOrderDetail(orderId) {
try {
const response = await fetch(`/api/orders/${orderId}`);
const data = await response.json();
return data;
} catch (e) {
Sentry.captureException(e);
}
}captureMessage
captureException와 유사하지만, 문자열로만 전송이 가능하다는 차이점이 존재한다.
import * as Sentry from "@sentry/react";
async function submitPayment(paymentInfo) {
try {
const result = await paymentService.process(paymentInfo);
if (!result.success) {
Sentry.captureMessage(`결제 실패: ${result.reason}`);
}
return result;
} catch (e) {
Sentry.captureMessage("결제 처리 중 알 수 없는 에러가 발생하였습니다!");
}
}Tags
Sentry의 가장 강력한 기능 중 하나인 Tags를 쓴다면 더욱 효과적으로 디버깅할 수 있다.
Tags power UI features such as filters and tag-distribution maps. Tags also help you quickly access related events and view the tag distribution for a set of events.
태그를 사용하면 관련 이벤트에 빠르게 접근하고 집합에 대한 분포를 확인할 수 있다. 태그는 키/값 문자열 쌍으로, Sentry가 해당 태그를 감지한 빈도와 마지막 시간까지 자동으로 색인화해준다.
태그 키의 최대 길이는 32자이며, 문자(a-zA-Z), 숫자(0-9), 밑줄(_), 마침표(.), 콜론(:), 대시(-)만 포함할 수 있고 공백은 사용할 수 없다.
import * as Sentry from "@sentry/react";
// 페이지 진입 시 태그 설정
Sentry.setTag("page_locale", "ko-kr");
Sentry.setTag("feature", "payment");
Sentry.setTag("environment", "production");필요한 정보만 모아보기
Event Level
이벤트 레벨에는 fatal, error, warning, log, info, debug가 있다.
아무 생각 없이 모든 레벨을 수집했다가는 금방 꽉 찰 거다. 그렇게 되면 과금이 많이 될 거고, 혼난다. 그렇기 때문에 칭찬을 받기 위해 필요한 정보만 수집할 수 있도록 해보자.
import * as Sentry from "@sentry/react";
Sentry.init({
dsn: process.env.REACT_APP_SENTRY_DSN,
beforeSend(event, hint) {
const level = event.level;
if (level === "info" || level === "debug") {
return null; // info, debug 레벨은 수집하지 않음
}
return event;
},
});이렇게 하면 특정 레벨만 수집하게 된다. 정말 모든 로그를 수집할 수 있다면 좋겠지만, 할당량이 꽉 차서 중요한 Error를 못 받는다면 의미가 없다.
그렇기 때문에 나는 개인적으로 프론트엔드에서는 Error만 수집하는데, 의미없는 400, 401, 404 같은 에러는 수집하지 않고 백엔드에서 로그를 전부 수집하는 식으로 처리를 한다.
마치며
Sentry를 사용한 지는 거의 3년 되는 것 같다. 하지만 그때마다 필요할 때 찾아서 사용했지, 한번도 깊게 찾아본 적도 없고 그냥 “남들이 사용하니까” 사용한 감이 있다. 하지만 다시 처음부터 시작하기로 마음먹은 만큼, 남들이 “Sentry 좋아요?”, “Sentry 쓰려고 하시는 이유가 뭐에요?” 라고 물었을 때 자신있게 대답할 수 있도록 정리해봤다.